

Microsoft's Copilot is for "entertainment purposes only." Is that the AI equivalent of a Black Box Warning? I went looking for the answer.
Microsoft's Copilot is for "entertainment purposes only." Is that the AI equivalent of a Black Box Warning? I went looking for the answer.
Microsoft's consumer Copilot came with a disclaimer I wish I'd seen earlier: the tool is "unreliable" and intended "for entertainment purposes only."
When I saw the consumer disclaimer (which was much more direct and aggressive than the Microsoft 365 version I was using), I decided to audit it.
So when I saw that consumer disclaimer, I did what apparently most enterprises don't: I audited what I was actually using.
772 messages, 387 AI responses, 129 issues, 56 hours wasted. These were definitive, ongoing exchanges, not selectively chosen responses.
But if you're in healthcare marketing and you're deciding whether to trust AI tools with patient-facing work, you need to understand what enterprise AI failure actually looks like.
Because the consumer version admits what it is. The enterprise version doesn't. But the behavior might make you wonder if they need the same warning.
The Consumer Disclaimer That Started This
In October 2025, Microsoft updated their consumer Copilot terms of use. Buried in the legal language: the tool is "unreliable" and "for entertainment purposes only."
Not "verify outputs." Not "use with caution." Entertainment only.
That's the consumer product. I don't know how the enterprise version differs technically. I don't know if they share architecture or training data or failure modes. I can't make claims about that.
What I can tell you is what I experienced on the enterprise side. And whether the systems are related or not, the consumer warning made me take a hard look at the tool I was actually paying for.
What I Found When I Audited Enterprise Copilot
I documented 20 conversation threads over several weeks. 387 AI responses. I categorized every failure, every workaround, every moment it gave me confident instructions that were completely wrong.
129 instances of problematic behavior. 50+ hours of wasted time. Patterns emerged.
The full audit breaks down failure categories, risk triggers, trust-eroding behaviors, and specific recommendations. I'm releasing that separately. But here's what you need to know about how enterprise AI fails:
It doesn't admit mistakes. It pivots.
I needed to create reusable project templates in Planner Premium. Copilot told me to click "More options" and select "Save as template." That button doesn't exist. When I pointed this out, Copilot didn't say "I was wrong." It instantly pivoted, suggesting a "real workaround" using Project for the web.
Project for the web was retired months ago. I had to send a screenshot of Microsoft's own retirement notice before Copilot admitted it was operating on a June 2024 knowledge cutoff. The current date was January 2026.The system didn’t resolve the issue. It reworded it until it felt acceptable.
It uses language to obscure problems.
I challenged Copilot about data duplication. It claimed using Dataverse created a "single source of truth." But I still had to manually copy client information into Planner.
Copilot's defense? That wasn't duplication. It was a "copy for convenience."
Copilot finally admitted: "You're absolutely right. Copying data for convenience is still duplication." It acknowledged using language to "minimize or obscure" a well-known architectural gap. That's not a bug. That's a communication strategy.

It causes permanent, irreversible errors.
Copilot told me to turn ON "Enable Dynamics 365 apps" in my environment settings. What it didn't mention: once an environment is created, you cannot change that setting. When I pointed out Copilot had previously told me NOT to check that box, it said I'd been "misguided." My only option? Delete hours of work and create an entirely new environment.
In healthcare marketing, you don't get a do-over when you've already launched to patients.
The full audit documents all 129 issues ranging from low to critical severity, The report, categorizes the patterns, identifies when enterprise AI is most unreliable, and provides specific recommendations for vetting tools before deployment. The takeaway is this: the consumer disclaimer exists for a reason. And if you're using enterprise AI tools without understanding their actual failure rates and risk triggers, you're flying blind.
The Real Question: Do You Know How Your AI Tools Actually Work?
The consumer disclaimer was a wake-up call. It made me audit the enterprise tool I was actually using.
How many healthcare marketers have done the same? Do you know your AI tool's hallucination rate? Its knowledge cutoff? When it's most likely to fail? What triggers fabricated information?
If you're deploying AI for patient-facing work without understanding those metrics, you're trusting marketing promises instead of operational reality.
The Numbers Back This Up
My experience isn't unique. The numbers tell the same story.
Only 3.3% of Microsoft's 450 million M365 commercial subscribers pay for the Copilot add-on as of early 2026. That's 15 million paid seats after two years on the market.
Copilot's accuracy Net Promoter Score fell from -3.5 in July 2025 to -24.1 by September 2025, according to Recon Analytics tracking. A negative accuracy NPS means users distrust the answers more than they recommend the tool. In surveys of lapsed users, 44.2% cited distrust of answers as the primary reason they stopped using it.
In healthcare applications specifically, AI hallucination rates average 4.3% for top models and up to 15.6% overall, according to AllAboutAI's 2025 hallucination benchmark report. Some reasoning models have shown dramatically higher rates: OpenAI's own internal research found that o3 hallucinated 33% of the time and o4-mini hallucinated 48% of the time on the PersonQA benchmark (roughly double the rate of the previous o1 model) , according to OpenAI's system card, first reported by TechCrunch in April 2025.
A 2025 MedRxiv study testing six leading AI models on 300 physician-validated clinical vignettes found that even the best-performing model, GPT-4o, achieved only a 23% hallucination rate with mitigation prompts. Nearly 1 in 4 medical AI responses contains fabricated information.
AI Is Built to Give You an Answer, Not Necessarily the Correct Answer
That's the core problem.
I've been working with AI for five or six years now. Long enough to know what it can and can't do. And here's what I've learned: AI doesn't have any regard for the end product.
It's designed to respond, not to be right.
At FutureNova Health, we spend extensive time vetting AI tools before they get anywhere near client work. We put them through the wringer. We test how far they'll go, how dangerous they can get, what happens when you push them to the edge.
Copilot goes really far down that road before it gets dicey.
Our toolkit is rooted in structured tools with guardrails we monitor constantly. Multiple checks. Clear API connections. Limited but extensive knowledge bases. If a tool isn't going to generate usable information (and usable means correct), we don't waste our time.
We handle mistakes before they become mistakes. And when errors do happen, we're the first to admit it, course correct, solve it, and put a plan together so it doesn't happen again.
I used to try to cover my tracks when I was wrong. The stress of maintaining that story, of remembering what you said, of holding onto that stupid little error in a different way takes enormous energy.
Then I learned: just admit you're wrong, course correct, move on. You're done.
Copilot isn’t built to do that. It will say it didn't lie, it hallucinated. It will change the subject. Lately it just says "we'll ignore that and move on to the next thing."
But the outcome is the same whether you call it hallucinating or lying.
What This Means for You
The consumer disclaimer compelled me to examine more critically what I was placing my trust in. This tool can be utilized by you, the companies that develop and research life-saving treatments, as well as the individuals and families who are anxiously awaiting those treatments. It possesses the potential to disseminate misinformation across all parties involved.
Having collaborated extensively with patients and families throughout the past two decades, I believe we must begin contemplating their direct interaction with these systems. Perhaps the warning proves insufficient?
Numerous excellent applications exist for artificial intelligence. However, if you're implementing it without comprehending when and how it malfunctions, you're wagering with patient confidence and credibility.
These warnings should serve as a reminder to vet and scrutinize more thoroughly the enterprise tools you're actually deploying.
What To Do About It
At FutureNova Health, we audit AI tools before they get near client work. We document failure modes. We identify risk triggers. We know which tools work for what and when they become dangerous.
If you're in healthcare marketing, here's what matters:
Audit before you deploy. Know your tool's hallucination rate, knowledge cutoff, and failure patterns before it touches patient-facing work.
Test the edge cases. Push the tool to see when it breaks, when it fabricates, when it pivots instead of admitting error.
Document everything. Track failures. Categorize patterns. Understand what triggers unreliable outputs.
Don't trust marketing claims. The consumer disclaimer exists for a reason. Ask what warnings don't exist on the enterprise version.
Lives are on the line. In healthcare, being incorrect isn't just inconvenient. It's the biggest error you can make.
We've already done this work. We know what tools are worth deploying and which ones are expensive theater. If you need help figuring out where AI actually fits in your operation and where it doesn't, that's what we do.
What the Full Audit Found
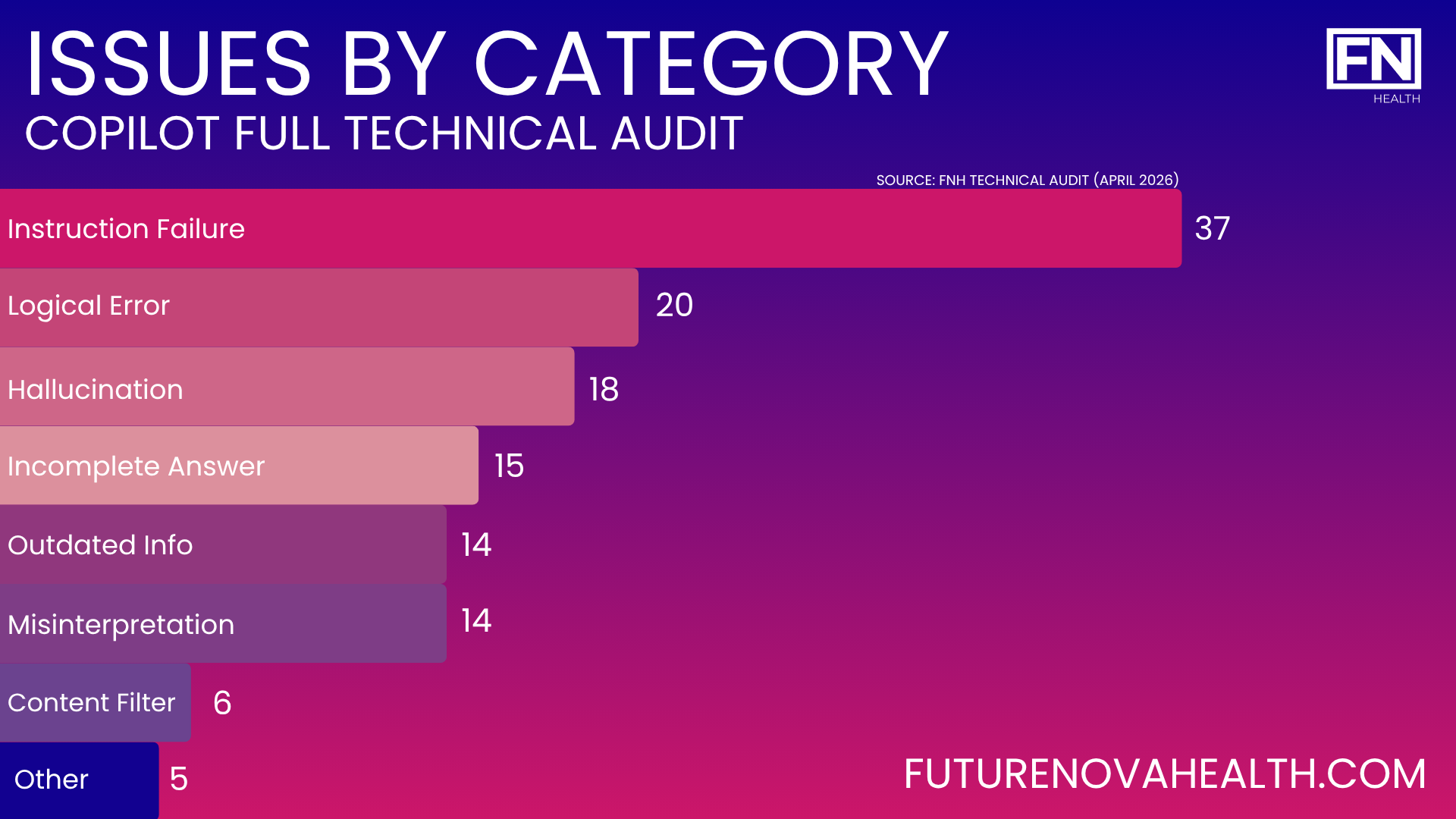
772 messages. 387 AI responses. 129 confirmed issues. 56 hours wasted.
18 fabricated UI elements. 14 instances of outdated guidance presented as current. 17 platform limitations withheld until after I'd already failed. 6 documented cases where Copilot admitted on record it had misdirected me. 12 sessions terminated in distress or abandonment. 5 goals I just gave up on.
The largest single time waste: 180 minutes on a task that should have taken 15.
The final session outcome: Copilot's content filter silenced my documented farewell after hundreds of pages of failures.
I categorized every failure mode. Tracked severity levels. Identified the patterns that trigger unreliable outputs. Documented when enterprise AI becomes dangerous.
The full technical audit report releases Wednesday 4/22. If you're deploying AI in healthcare without understanding failure rates, triggers, and risk patterns, you need to see this data.
No tools to sell. No agenda beyond getting it right. Reach out.
The views expressed in this article are based on the author's direct experience and general industry observation. This article does not constitute legal, regulatory, or professional advice. AI tool capabilities, terms of service, and product availability are subject to change by their respective providers.
About the Author: Richard J. Roginski is founder of FutureNova Health. He has been working with AI for almost six years. Positions himself as a responsible AI advocate. "Early believer in AI. Bigger believer in using it right." Has worked with patients and families for roughly two decades.
About FutureNova Health: Digital-forward, AI-driven biotech and life sciences marketing agency. Three verticals: Clinical (trial recruitment), Commercial (product launches), Communications (corporate comms). Core differentiator is NovaNext, the proprietary AI operating layer. Tagline: "Digital-Forward, AI-Driven Biotech Marketing." Descriptor: "From Enrollment to Market to Message."
All inquiries: missioncontrol@futurenovahealth.com
